这边有个性能要求极高的api要上线,这个服务端是golang http模块实现的。在上线之前我们理所当然的要做压力测试。起初是 “小白同学” 起头进行压力测试,但当我看到那压力测试的结果时,我也是逗乐了。 现象是,直接访问Golang http api是每秒可以到3.5W的访问, 为了理论承受更强的QPS,多开了几个go http api进程端口,又在这前面加了层nginx负载均衡,结果往nginx压测的结果是每秒才可以解决1.5w的访问量。 这结果让高级黑 “小白” 把nginx又给鄙视了。
虽然哥平时开发任务很饱和,又因为带几个新人的原因,有点心累。 但哥还是抽出宝贵的时间来解决nginx在压力测试下性能上不去的问题。 哈哈,这里肯定有人要打我了。 说实话,做运维虽然能时常碰一些负载均衡调度器,但由于很多时候配置都标准化了,新开一个业务线,把配置一scp,然后选择性的修改域名及location就可以了,还真是没遇到过这次的问题。
我们在寻找性能瓶颈的是时候,会频繁的使用后面的工具进行监控,推荐大家使用tmux或者screen开启多个终端监控,用top可以看到nginx及go api的cpu占用率,load值,run数,各个cpu核心的百分比,处理网络的中断。用dstat可以看到流量及上下文切换的测试。 ss + netstat 查看连接数。
首先是压力测试的方法问题
以前做运维的时候,我们一般不会用简单的ab来进行压测,这样会造成压力源过热的情况,正常的针对服务端测试的方法是,分布式压力测试,一个主机压测的结果很是不准,当然前提是 服务端的性能够高,别尼玛整个python django就用分布式压测,随便找个webbench,ab , boom这类的http压测就可以了。
关于客户端压测过热的情况有几个元素,最主要的元素是端口占用情况。首先我们需要明确几个点, 作为服务端只是消耗fd而已,但是客户端是需要占用端口来发起请求。 如果你自己同时作为服务端和客户端,会被受限于65535-1024的限制,1024内一般是常规的系统保留端口。 如果你按照65535-1024计算的话,你可以占用64511端口数,但如果你是自己压力测试nginx,然后nginx又反向代理几个golang http api。 那么这端口被严重的缩水了。 当你压测的数目才6w以上,很明显报错,不想报错,那么只能进行排队阻塞,好让客户端完成该请求。
另外一点是nginx 配置问题。
这一点很重要,也是最基本的要求,如果nginx worker连接数过少的化,你的请求连接就算没有被阻塞到backlog队列外,nginx worker也会因为过载保护不会处理新的请求。nginx的最大连接数是worker num *worker_connections, 默认worker_connections是1024, 直接干到10w就可以了。
在我们配置调整之后,访问的速度有明显的提升,但还是没有达到我们的预期。 接着通过lsof追了下进程,发现nginx 跟 后端创建了大量的连接。 这很明显是没有使用http1.1长连接导致的,使用tcpdump抓包分析了下,果然是http1.0短链接,虽然我们在sysctl内核里做了一些网络tcp回收的优化,但那也赶不上压力测试带来的频繁创建tcp的消耗。 果然在upstream加了keepalive。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
# xiaorui.cc
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
python 538 ruifengyun 9u IPv4 595559383 0t0 TCP 58.215.141.194:46665->58.215.141.83:9001 (ESTABLISHED)
test_dic4 7476 ruifengyun 5u IPv6 660251515 0t0 TCP *:9001 (LISTEN)
test_dic4 7476 ruifengyun 10u IPv6 660870187 0t0 TCP localhost:9001->localhost:46679 (ESTABLISHED)
test_dic4 7476 ruifengyun 13u IPv6 660870138 0t0 TCP localhost:9001->localhost:46608 (ESTABLISHED)
test_dic4 7476 ruifengyun 14u IPv6 660870137 0t0 TCP localhost:9001->localhost:46607 (ESTABLISHED)
test_dic4 7476 ruifengyun 22u IPv6 660870153 0t0 TCP localhost:9001->localhost:46632 (ESTABLISHED)
test_dic4 7476 ruifengyun 23u IPv6 660870143 0t0 TCP localhost:9001->localhost:46618 (ESTABLISHED)
test_dic4 7476 ruifengyun 27u IPv6 660870166 0t0 TCP localhost:9001->localhost:46654 (ESTABLISHED)
test_dic4 7476 ruifengyun 73u IPv6 660870191 0t0 TCP localhost:9001->localhost:46685 (ESTABLISHED)
test_dic4 7476 ruifengyun 85u IPv6 660870154 0t0 TCP localhost:9001->localhost:46633 (ESTABLISHED)
test_dic4 7476 ruifengyun 87u IPv6 660870147 0t0 TCP localhost:9001->localhost:46625 (ESTABLISHED)
....
|
摘录官方文档的说明如下。该参数开启与上游服务器之间的连接池,其数值为每个nginx worker可以保持的最大连接数,默认不设置,即nginx作为客户端时keepalive未生效。
Activates cache of connections to upstream servers
The connections parameter sets the maximum number of idle keepalive connections to upstream servers that are retained in the cache per one worker process. When this number is exceeded, the least recently used connections are closed
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
# xiaorui.cc
upstream http_backend {
server 127.0.0.1:8080;
keepalive 256;
}
server {
...
location /http/ {
proxy_pass http://http_backend;
proxy_http_version 1.1;
proxy_set_header Connection “”;
...
}
}
|
继续进行压力测试,返现这访问量还是那样,没有什么提升,通过排除问题确认又是连接数大引起的,这长连接不生效呀。 以前我在线上也是这么调配的,应该没问题。 最后通过nginx error log找到了原因。 这Nginx版本居然不支持keepalive 长连接,没招,换个版本再次测试。
|
1
2
3
4
5
6
7
8
9
10
|
2016/06/24 16:34:12 [error] 15419#0: *9421660 connect() failed (111: Connection refused) while connecting to upstream, client: 10.1.1.58, server: , request: “GET / HTTP/1.0”, upstream: “http://127.0.0.1:9001/”, host: “10.1.1.63”
2016/06/24 16:34:12 [error] 15418#0: *9423639 connect() failed (111: Connection refused) while connecting to upstream, client: 10.1.1.58, server: , request: “GET / HTTP/1.0”, upstream: “http://127.0.0.1:9004/”, host: “10.1.1.63”
2016/06/24 16:34:12 [error] 15418#0: *9423639 no live upstreams while connecting to upstream, client: 10.1.1.58, server: , request: “GET / HTTP/1.0”, upstream: “http://test_servers/”, host: “10.1.1.63”
2016/06/24 16:34:12 [error] 15418#0: *9393899 connect() failed (111: Connection refused) while connecting to upstream, client: 10.1.1.58, server: , request: “GET / HTTP/1.0”, upstream: “http://127.0.0.1:9004/”, host: “10.1.1.63”
2016/06/24 16:58:13 [notice] 26449#26449: signal process started
2016/06/24 16:58:13 [emerg] 27280#0: unknown directive “keepalive” in /etc/nginx/conf.d/test_multi.conf:7
2016/06/24 17:02:18 [notice] 3141#3141: signal process started
2016/06/24 17:02:18 [emerg] 27280#0: unknown directive “keepalive” in /etc/nginx/conf.d/test_multi.conf:7
2016/06/24 17:02:44 [notice] 4079#4079: signal process started
2016/06/24 17:02:44 [emerg] 27280#0: unknown directive “keepalive” in /etc/nginx/conf.d/test_multi.conf:7
|
简单描述下nginx upstream keepalive是个怎么一回事?
默认情况下 Nginx 访问后端都是用的短连接(HTTP1.0),一个请求来了,Nginx 新开一个端口和后端建立连接,请求结束连接回收。
如过配置了http 1.1长连接,那么Nginx会以长连接保持后端的连接,如果并发请求超过了 keepalive 指定的最大连接数,Nginx 会启动新的连接 来转发请求,新连接在请求完毕后关闭,而且新建立的连接是长连接。
下图是nginx upstream keepalive长连接的实现原理.
首先每个进程需要一个connection pool,里面都是长连接,多进程之间是不需要共享这个连接池的。 一旦与后端服务器建立连接,则在当前请求连接结束之后不会立即关闭连接,而是把用完的连接保存在一个keepalive connection pool里面,以后每次需要建立向后连接的时候,只需要从这个连接池里面找,如果找到合适的连接的话,就可以直接来用这个连接,不需要重新创建socket或者发起connect()。这样既省下建立连接时在握手的时间消耗,又可以避免TCP连接的slow start。如果在keepalive连接池找不到合适的连接,那就按照原来的步骤重新建立连接。 我没有看过nginx在连接池中查找可用连接的代码,但是我自己写过redis,mysqldb的连接池代码,逻辑应该都是一样的。谁用谁pop,用完了再push进去,这样时间才O(1)。
如果你的连接池的数控制在128,但因为你要应对更多的并发请求,所以临时又加了很多的连接,但这临时的连接是短连接和长连接要看你的nginx版本,我这1.8是长连接,那他如何被收回,两地保证,一点是他会主动去释放,另一点是keepalive timeout的时间。
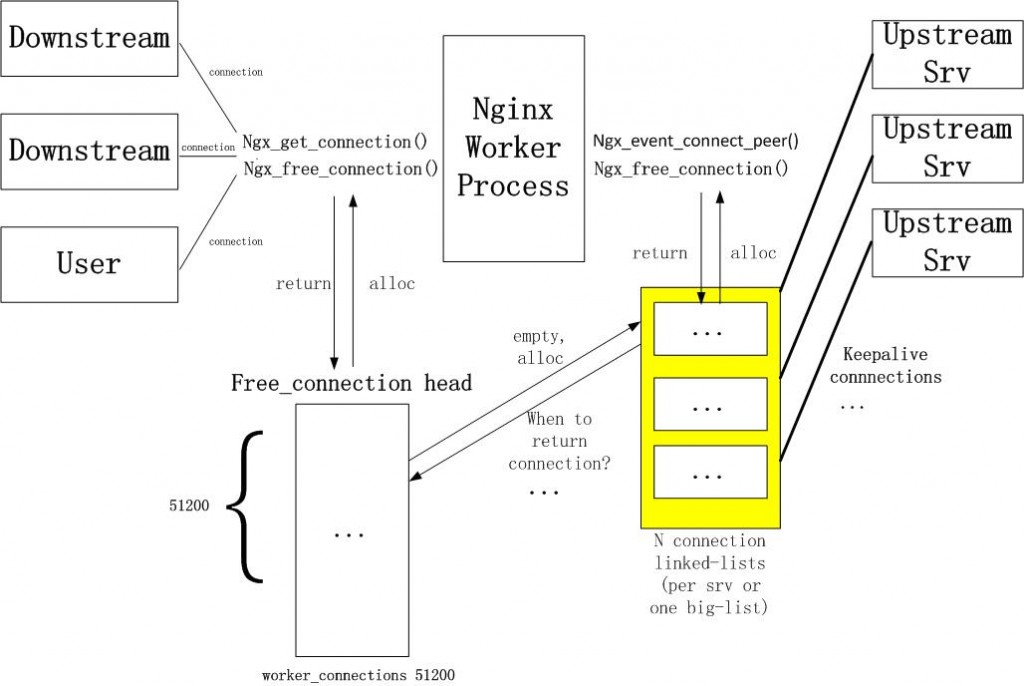
Golang的http模块貌似对http spdy支持不怎么好, 要不然可以直接用淘宝的tengine upstream spdy的方式连接后端Server。 他的速度要比keepalive要好的多,毕竟省去了等待上次返回的结果的过程。
原文地址: